

This article series helps us to work on a special use case of extracting information of word documents uploaded to Office 365 SharePoint libraries and then analyze the document content using Azure Cognitive Services.
We have seen before extracting tags and metadata properties of image files from Office 365 SharePoint using Microsoft Flow and Azure Cognitive Services.
Microsoft Flow has a Get File content action, but that doesn't help extracting word documents content. Only it supports extracting content of notepad as straight forward approach. Since Microsoft Flow doesn't provide any option to read the word documents content, we will be using Azure Functions to extract the content. Once we have the content, we will use Azure Cognitive service to get the tags for the content extracted. Here Microsoft Flow is used to manipulate triggers and subsequent actions. So our algorithm is will be as follows.
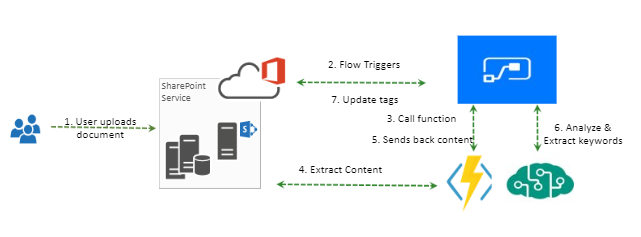
Word document is uploaded to Office 365 SharePoint library.
Microsoft Flow will be listening the library for any document uploads. (When an file is created). This trigger is configured to look for any document uploads. Extract the properties of documents (like File Path, Id, etc.)
Call Azure function/service to read document content
From Azure function, read the content of the document using file path with the help of client context.
Sends document content back to Microsoft Flow
Analyze the text to extract key phrases using Azure Cognitive services.
Update the SharePoint item (document) properties with tags extracted using Cognitive Service.
This particular part helps in extracting the content of the document using file path with the help of azure function and SharePoint client context.
Extracting Content Using Azure Function
The custom service to read the content of word document, is being hosted as Azure Function. The custom service or function is being built using C# HTTP Trigger templates with the help of SharePoint PnP libraries to extract the content of file uploaded to SharePoint libraries.
This Azure Function requires a file path, to read the file content. Let us first see how the content is extracted using Azure Function.
Using the file path, the file content is retrieved from SharePoint with the help of open XML SDKs. The following is a XML structure for any of the word document. This structure just shows the document content elements, which doesn't show any style elements (since style elements are not required for this POC).
<w:document xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<w:body>
<w:p>
<w:r>
<w:t>Creating Document Libraries</w:t>
</w:r>
</w:p>
<w:p>
<w:r>
<w:t>Create a document library in SharePoint Online or SharePoint Server 2016, 2013, 2010, or 2007 to securely store files where you and your co-workers can find them easily, work on them together, and access them from any device at any time. SharePoint team sites include a document library by default, however, you can add additional document and other libraries to a site as needed. For more information about document libraries, see
</w:t>
</w:r>
</w:p>
</w:body>
</w:document>
The following snippet helps you retrieving the content of file by parsing XML.
public static string ExtractContentFromWordDocument(MemoryStream filePath)
{
// open xml namespace format for processing documents
string xmlNamespace = "http://schemas.openxmlformats.org/wordprocessingml/2006/main"; StringBuilder textBuilder = new StringBuilder();
using (WordprocessingDocument processDocument = WordprocessingDocument.Open(filePath, false)) {
NameTable nameTable = new NameTable();
XmlNamespaceManager xmlNamespaceManager = new XmlNamespaceManager(nameTable); xmlNamespaceManager.AddNamespace("w", xmlNamespace);
// Extract all paragraphs from document XML
XmlDocument xmlDocument = new XmlDocument(nameTable); xmlDocument.Load(processDocument.MainDocumentPart.GetStream());
XmlNodeList paragraphNodes = xmlDocument.SelectNodes("//w:p", xmlNamespaceManager);
// Parse through each paragraph nodes
foreach (XmlNode paragraphNode in paragraphNodes)
{
// Get only text nodes, excluding the other formatting options
XmlNodeList textNodes = paragraphNode.SelectNodes(".//w:t", xmlNamespaceManager);
// Append only text content to the custom string builder
foreach (XmlNode textNode in textNodes)
{
textBuilder.Append(textNode.InnerText);
}
textBuilder.AppendLine();
}
}
return textBuilder.ToString();
}
The following snippet shows how the data is retrieved from the SharePoint by extracting the document content.
[FunctionName("readspdocuments")]
public static async Task<HttpResponseMessage> Run([HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)]HttpRequestMessage req, TraceWriter log)
{
log.Info("C# HTTP trigger function processed a request.");
// Credentials for getting authenticated context using auth manager of OfficeDevPnP Dll
// Since its a POC, I have used direct creds.
// You could use other authentication modes for getting the context for PRODUCTION ENV usage. string siteUrl = "https://nakkeerann.sharepoint.com/sites/teamsite";
string userName = "nav@nakkeerann.onmicrosoft.com";
string password = "*****";
OfficeDevPnP.Core.AuthenticationManager authManager = new OfficeDevPnP.Core.AuthenticationManager();
// parse query parameter
string filePath = req.GetQueryNameValuePairs()
.FirstOrDefault(q => string.Compare(q.Key, "filePath", true) == 0)
.Value;
try
{
// context using auth manager
using (var clientContext = authManager.GetSharePointOnlineAuthenticatedContextTenant(siteUrl, userName, password))
{
Web web = clientContext.Site.RootWeb;
Microsoft.SharePoint.Client.File file = web.GetFileByUrl(filePath);
var data = file.OpenBinaryStream();
string content = null;
using (MemoryStream memoryStream = new MemoryStream())
{
clientContext.Load(file);
clientContext.ExecuteQuery();
if (data != null && data.Value != null)
{
data.Value.CopyTo(memoryStream);
memoryStream. Seek (0, SeekOrigin.Begin);
// Function extracts the document content
content = ExtractContentFromWordDocument(memoryStream);
// Function responds back with extracted document content
return req.CreateResponse(HttpStatusCode.OK, content);
}
}
// Function responds back
return req.CreateResponse(HttpStatusCode.BadRequest, "Unable to process file or no content present");
}
}
catch (Exception ex)
{
log.Info("Error Message: " + ex.Message);
return req.CreateResponse(HttpStatusCode.BadRequest, ex.Message);
}
}
In the next post, let us look how to host and integrate this function into Microsoft flow for extracting and updating tags.
Comments