
SQL joins are a fundamental aspect of working with relational databases. They allow us to combine data from multiple tables based on common columns, enabling us to extract valuable insights. In this article, we'll explore the basics of SQL joins, including their purpose, syntax, and different types. By the end, you'll have a solid understanding of how joins work and how to leverage them for efficient data analysis. Let's dive in and unlock the power of SQL joins!
What is SQL Joins?
SQL joins are used to combine rows from two or more tables based on a related column between them. They allow you to retrieve data from multiple tables in a single query.
Imagine you have two tables: Table A and Table B. A join operation allows you to match rows from Table A with corresponding rows from Table B based on a common column or relationship.

Joining data can sometimes be more complex than in the previous example. In certain situations, we may encounter rows that cannot be joined because the joining column doesn't have the same value in both tables.
For example, consider a scenario where there is no quantity listed for "apple" in the given example. How we handle such rows depends on the type of SQL join we use.

There are four main types of joins: inner join, left join, right join, and full join. In this article, I’ll explain to you what each type entails.

What is an Inner Join?
An inner join is a type of SQL join that returns only the matching rows from both tables based on the specified join condition. It combines the rows from two tables where the join condition is satisfied.
Here's an example to illustrate how an inner join works:
Suppose we have two tables: "Customer" and "Customer_Order".


To retrieve the customer name and their corresponding orders, we can use an inner join:
SELECT Customer.Customer_Name, Customer_Order.Product
FROM Customer
INNER JOIN Customer_Order ON Customer.CustomerID = Customer_Order.CustomerID;The result of this query would be:

In this example, the inner join combines the rows from the "Customers" table and the "Orders" table where the CustomerID matches in both tables. Only the matching rows are returned, resulting in the customer name along with their corresponding products.
What is a Left Join?
A left join is a type of SQL join that returns all the rows from the left table and the matching rows from the right table based on the specified join condition. If there is no match in the right table, it returns null values for the columns of the right table.
Here's an example to demonstrate how a left join works:
Consider the two tables: Customer and Customer_Order".
To retrieve all customers and their corresponding orders (if any), we can use a left join:
SELECT Customer.Customer_Name, Customer_Order.Product
FROM Customer
LEFT JOIN Customer_Order ON Customer.CustomerID = Customer_Order.CustomerID;In this example, the left join includes all the rows from the "Customers" table and the matching rows from the "Orders" table based on the CustomerID. Since Satty has no matching order, a null value is displayed for the "Product" column in her row.
The left join ensures that all customers are included in the result, even if they do not have any matching orders.
What is the Right Join?
A right join is a type of SQL join that returns all the rows from the right table and the matching rows from the left table based on the specified join condition. If there is no match in the left table, it returns null values for the columns of the left table.
In other words, a right join is essentially the reverse of a left join. It ensures that all rows from the right table are included in the result, along with the matching rows from the left table.
When performing a right join, the result will contain all the rows from the right table and only the matching rows from the left table. If there is no match in the left table, null values are displayed for the columns of the left table.
Consider the two tables: Customers and Orders
Table: Customers

Table: Orders

To retrieve all orders and their corresponding customer information (if available), we can use a right join:
SELECT Customers.CustomerName, Orders.Product
FROM Customers
RIGHT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;The result of this query would be:

In this example, the right join includes all the rows from the "Orders" table and the matching rows from the "Customers" table based on the CustomerID. Since there is no matching customer for the "Printer" order, a null value is displayed for the "CustomerName" column in that row.
The right join ensures that all orders are included in the result, even if they do not have a corresponding customer.
What is a Full Join?
A full join, also known as a full outer join, is a type of SQL join that returns all the rows from both the left and right tables, including both the matching and non-matching rows. It combines the results of both a left join and a right join.
To retrieve all customers and their corresponding orders, including non-matching rows, we can use a full join:
SELECT Customers.CustomerName, Orders.Product
FROM Customers
FULL JOIN Orders ON Customers.CustomerID = Orders.CustomerID;The result of the query is:

In this example, the full join includes all the rows from both the "Customers" and "Orders" tables. It combines the matching rows based on the CustomerID and includes the non-matching rows from both tables. Since there is no matching customer for the "Printer" order, a null value is displayed for the "CustomerName" column in that row.
The full join ensures that all rows from both tables are included in the result, providing a comprehensive view of the data from both tables.
What if the table has duplicate data?
When joining tables in SQL, the presence of duplicates in one table can affect the result of the join, depending on the type of join used. If there are duplicates in one table, they will also appear in the joined table, potentially resulting in repeated data.
To better understand this, let's consider an example using two tables, File One and File Two, and perform an inner join on the "Item" column.
Table: File_One
Create table File_One (Item VARCHAR(20), Quantity INT);
INSERT INTO File_One (Item, Quantity) VALUES ('Orange', 5);
INSERT INTO File_One (Item, Quantity) VALUES ('Apple', 3);
INSERT INTO File_One (Item, Quantity) VALUES ('Orange', 10);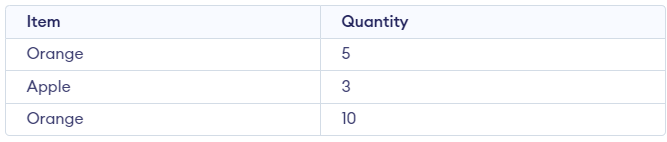
Table: File_Two
Create table File_Two (Item VARCHAR(20), Price VARCHAR(20));
INSERT INTO File_Two (Item, Price) VALUES ('Orange', '$1.50');
INSERT INTO File_Two (Item, Price) VALUES ('Banana', '$0.75');
INSERT INTO File_Two (Item, Price) VALUES ('Apple', '$0.90');
In File One, we have two rows with the item "Orange," while in File Two, there is only one row with "Orange." Let's perform an inner join on the "Item" column:
SELECT File_One.Item, File_One.Quantity, File_Two.Price
FROM File_One
INNER JOIN File_Two ON File_One.Item = File_Two.Item;The result of this query would be:

As you can see, the "Orange" item is repeated in the joined table because there were duplicates in File One. The matching row from File Two is repeated for each instance of "Orange" in File One. On the other hand, the "Apple" row appears only once since there were no duplicates in either table.
This behavior is important to consider when joining tables, as it can impact the resulting dataset and potentially lead to unintended duplication of data. It's crucial to understand the data in both tables and the join conditions to accurately interpret the output of the join operation.
How do Join tables with multiple columns in common?
Yes, it is possible to join tables based on multiple columns, and each combination of values in the specified columns will be treated as a unique entity.
Let's consider an example where we perform a full join on the "Item" and "Price" columns. This means that we will match rows based on both the "Item" and "Price" values from two tables.
Table: Table1
Create table Table1 (Item VARCHAR(20), Price VARCHAR(20), Quantity INT);
INSERT INTO Table1 (Item, Price, Quantity) VALUES ('Orange','$1.50', 5);
INSERT INTO Table1 (Item, Price, Quantity) VALUES ('Apple','$0.90', 3);
INSERT INTO Table1 (Item, Price, Quantity) VALUES ('Orange','$1.25', 6);
Table: Table2
Create table Table2 (Item VARCHAR(20), Price VARCHAR(20), Stock INT);
INSERT INTO Table2 (Item, Price, Stock) VALUES ('Orange','$1.50', 10);
INSERT INTO Table2 (Item, Price, Stock) VALUES ('Banana','$0.75', 6);
INSERT INTO Table2 (Item, Price, Stock) VALUES ('Apple','$0.90', 5);
To perform a full join on both the "Item" and "Price" columns, we would use the following query:
SELECT Table1.Item, Table1.Price, Table1.Quantity, Table1.Stock
FROM Table1
FULL JOIN Table2 ON Table1.Item = Table1.Item AND Table1.Price = Table2.Price;The result of this query would be:

In this example, the row with "Apple" is merged because it has the same "Item" and "Price" values in both tables. However, the two "Orange" rows are treated as different entities because their "Price" values are different.
The full join considers each combination of "Item" and "Price" as separate entities, resulting in all possible matches and non-matches being included in the result. If a match is not found for a specific combination, null values are displayed for the corresponding columns.
Joining tables based on multiple columns allows for more precise matching criteria and can help capture specific combinations of data across the tables.
What if I have a blank value in the table?
When joining tables, if you have a blank value in the common column you're joining on, it will be treated like any other value, and the join operation will proceed as usual.
Let's consider an example using two tables, File One and File Two, where there are blank values in the "Item" column of both files. We will perform a left join on the "Item" and "Price" columns.
Table: Table1
Create table Table1 (Item VARCHAR(20), Price VARCHAR(20), ID INT, Quantity INT);
INSERT INTO Table1 (Item, Price, ID, Quantity) VALUES ('Orange','$1.50', 123 ,10);
INSERT INTO Table1 (Item, Price, ID, Quantity) VALUES ('Apple','$1.75', 456 ,3);
INSERT INTO Table1 (Item, Price, ID, Quantity) VALUES ('','$0.90', 789,'');
INSERT INTO Table1 (Item, Price, ID, Quantity) VALUES ('', '', 101 ,6);
Table: Table2
Create table Table2 (Item VARCHAR(20), Price VARCHAR(20), Stock INT);
INSERT INTO Table2 (Item, Price, Stock) VALUES ('','$1.50',10);
INSERT INTO Table2 (Item, Price, Stock) VALUES ('','$1.75',32);
INSERT INTO Table2 (Item, Price, Stock) VALUES ('Orange','$0.90',25 );
Performing a left join on the "Item" and "Price" columns, using the following query:
SELECT Table1.Item, Table1.Price, Table1.ID, Table1.Quantity, Table2.Stock
FROM Table1
LEFT JOIN Table2 ON Table1.Item = Table2.Item AND Table1.Price = Table2.Price;The result of this query would be:

In this example, the blank values in the "Item" column are treated as regular values, and the join operation proceeds accordingly. The left join includes all rows from File One, regardless of whether they have matches in File Two.
The row with "Orange" and "$1" in both files is merged, and the corresponding ID# and Quantity values are displayed. The row with "Apple" and "$1" is also included, even though it has no match in File Two, resulting in NULL values for the Stock column.
The blank row with "$2" in File One remains as is, with a NULL value for Stock. Similarly, the blank rows in File Two are included in the result, with NULL values for the other columns.
It's important to note that while blank values are treated like any other string, NULL values are different. NULL values represent the absence of data and are treated as unique entities. They cannot be joined on and are typically used to indicate missing or unknown values.
Joining tables with blank values in the common column allows for the inclusion of those rows in the join operation while ensuring the proper handling of NULL values in the result set.
Comments