
SQL interviews are crucial for individuals seeking roles in data management and database systems. This article provides a concise collection of commonly asked SQL interview questions along with comprehensive answers. By reviewing these questions and explanations, you can enhance your SQL skills and confidently tackle SQL-related interviews. Let's explore a curated selection of SQL interview questions to boost your readiness for your next interview.

SQL Interview Questions and Answers
Question 1: What is an index? What are the two main index types?
An index is a database structure designed to enhance data retrieval speed. When performing a search on a table using an SQL query, the database typically scans the entire table to find the desired data and return the results. However, if a table is unindexed, it is referred to as a heap, where data is generally stored without any specific arrangement. This means that searching for data in an unindexed table can be slow and frustrating.
When querying an indexed table, the database utilizes the index to locate the relevant records directly. There are two main types of indexes:
Clustered Index: A clustered index determines the precise order in which the data is physically stored within the table. Each table can have only one clustered index since the data can be ordered in just one way. The clustered index effectively determines the physical organization of the table.
Non-clustered Index: Unlike a clustered index, a non-clustered index does not dictate the physical order of the data within the table. Instead, it simply provides pointers to the data. The non-clustered index is stored separately from the actual data and maintains its own order, which may not correspond to the physical order of the data.
Both index types offer distinct advantages. A clustered index speeds up data retrieval when queries align with the index order. On the other hand, non-clustered indexes excel at enhancing search performance for specific columns or non-sequential data, as they allow for quicker access to relevant records without rearranging the physical data.
Question 2: How to create an index?
Suppose we have the table employee, which has the following columns:
Name – The employee’s first name.
Surname – The employee’s last name.
nin – The employee’s national identification number (e.g. social security number).
To create a clustered index on the nin column and a non-clustered index on the surname column, consider the below code:
To create a clustered index on the "nin" column:
CREATE CLUSTERED INDEX CL_nin
ON employee(nin);This code will create a clustered index named "CL_nin" on the "nin" column of the "employee" table.
To create a non-clustered index on the "Surname" column:
CREATE NONCLUSTERED INDEX NCL_Surname
ON employee(Surname);Executing this code will create a non-clustered index named "NCL_surname" on the "surname" column of the "employee" table.
Question 3: How to add rank to rows?
Monitoring sales numbers is important for any company, such as a car dealership company. Let's consider a scenario where multiple Sales people are selling cars on a daily basis. In this case, the dealership management has a vested interest in evaluating and comparing the performance of their salespeople.
Our goal is to identify high-performing individuals and differentiate them from those who are not meeting expectations or underperforming.
For example, you have the table Cars_Details which includes First_Name, Last_Name and Cars_Sold:
Create table Cars_Details (First_Name VARCHAR(50), Last_Name VARCHAR(50), Cars_Sold INT);
INSERT INTO Cars_Details(First_Name, Last_Name, Cars_Sold) VALUES ('Rahul', 'Sharma', 64);
INSERT INTO Cars_Details(First_Name, Last_Name, Cars_Sold) VALUES ('Aishwarya', 'Mahajan', 97);
INSERT INTO Cars_Details(First_Name, Last_Name, Cars_Sold) VALUES ('Pranav', 'Mishra', 35);
INSERT INTO Cars_Details(First_Name, Last_Name, Cars_Sold) VALUES ('Shanky', 'Singh', 24);
INSERT INTO Cars_Details(First_Name, Last_Name, Cars_Sold) VALUES ('Vibhu', 'Yadav', 89);
INSERT INTO Cars_Details(First_Name, Last_Name, Cars_Sold) VALUES ('Sofia', 'Virdi', 102);
INSERT INTO Cars_Details(First_Name, Last_Name, Cars_Sold) VALUES ('Satty', 'Singh', 51);Output:
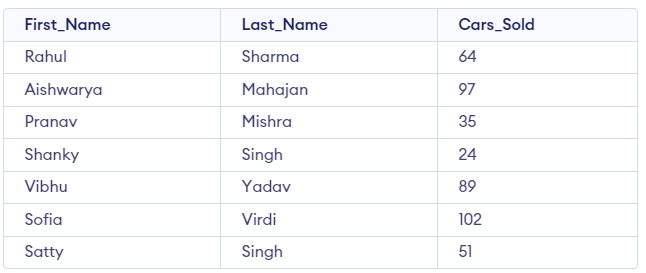
Query:
SELECT RANK() OVER(ORDER BY cars_sold DESC) AS rank_sales,
First_Name,
Last_Name,
Cars_sold
FROM Cars_Details;The given SQL query retrieves data from the "Cars_Details" table and generates a ranking for each row based on the number of cars sold. Here's a simplified explanation of the query:
The "RANK() OVER(ORDER BY cars_sold DESC)" expression generates a ranking for each row based on the number of cars sold. The "DESC" keyword specifies that the ranking should be in descending order, meaning the highest number of cars sold will have the highest rank.
The "AS rank_sales" rename the generated ranking column as "rank_sales" for clarity.
Output:
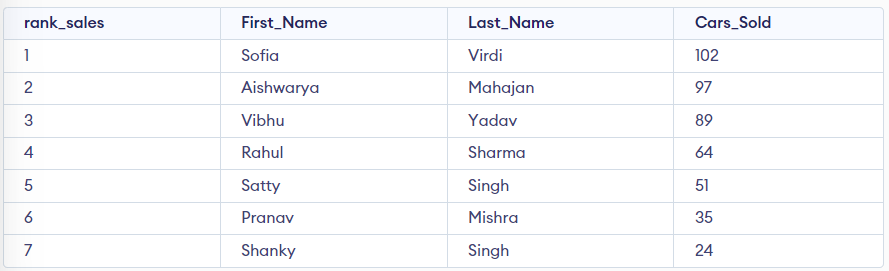
Question 4: What is the difference between RANK() and DENSE_RANK()?
When comparing the RANK() and DENSE_RANK() functions, the main difference lies in how they handle rows with the same values in the ranking criteria.
RANK():
The RANK() function assigns the same rank to all rows that have identical values in the ranking criteria. If multiple rows share the same rank, RANK() will skip subsequent ranks to maintain uniqueness. The number of skipped ranks depends on the number of rows with the same value. This means that RANK() generates non-consecutive ranks.
DENSE_RANK():
On the other hand, the DENSE_RANK() function behaves similarly to RANK() by assigning the same rank to rows with the same values in the ranking criteria. However, DENSE_RANK() does not skip any ranks. Instead, it provides consecutive ranks without any gaps.
Consider the table "Cars_Details":
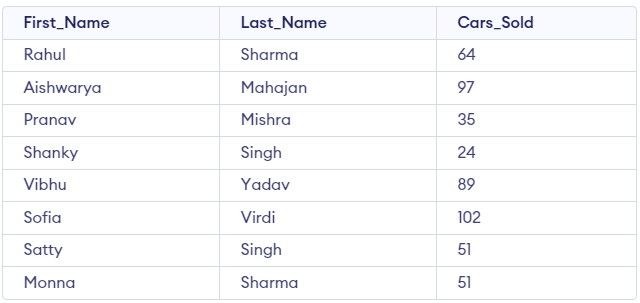
Run the query RANK():
SELECT RANK() OVER(ORDER BY cars_sold DESC) AS rank_sales,
First_Name,
Last_Name,
Cars_sold
FROM Cars_Details;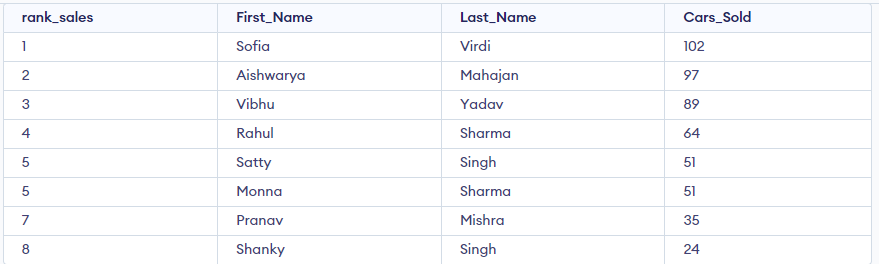
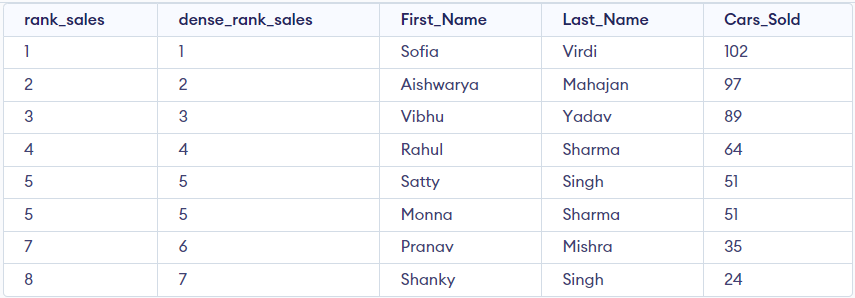
In the above output, you must notice that rank 5 is allocated twice, then the ranking skips 6 and goes directly to 7.
Consider the following code to use DENSE_RANK() ranks the rows, run the following code:
SELECT RANK() OVER(ORDER BY cars_sold DESC) AS rank_sales,
DENSE_RANK () OVER (ORDER BY cars_sold DESC) AS dense_rank_sales,
First_Name,
Last_Name,
Cars_Sold
FROM Cars_Details;Output:
Question 5: What is an auto-increment?
Any type of database job will require this knowledge. Auto-increment is a SQL function that automatically and sequentially creates a unique number whenever a new record is added to the table.
The keyword that’ll give you this function is AUTO_INCREMENT.
Here’s an example. The code below will create the table names with the values defined by INSERT INTO:
CREATE TABLE Employees (
Employee_ID INT AUTO_INCREMENT PRIMARY KEY,
First_Name VARCHAR(50),
Last_Name VARCHAR(50)
);
INSERT INTO Employees (First_Name, Last_Name) VALUES ('Rahul', 'Sharma');
INSERT INTO Employees (First_Name, Last_Name) VALUES ('Shanky', 'Singh');
INSERT INTO Employees (First_Name, Last_Name) VALUES ('Pranav', 'Mishra');Now, run the below query:
To see how the auto-increment function works, add a new record to the table above:
INSERT INTO Employees (First_Name, Last_Name) VALUES ('Sofia', 'Virdi');This will add a new record to a table. Select all the data to see how the table has changed:
SELECT *
FROM Employees;When we added a new record to the table, AUTO_INCREMENT automatically added a new sequential number. As 1 and 2 previously existed in the table, with AUTO_INCREMENT the database knows that the next value will be 3.
Question 6: What is a subquery?
A subquery, also known as an inner query or nested query, is a query that is placed within another query. It is used to retrieve data that will be utilized by the main query. Typically, you will find a subquery incorporated within the WHERE clause.
For example, let's consider a scenario where we have two tables: "Customers" and "Orders." We want to retrieve the names of customers who have placed orders with a total amount greater than a certain threshold. In this case, we can use a subquery to retrieve the relevant order information and then incorporate it into the main query to obtain the desired result.
Here's an example SQL query that demonstrates the usage of a subquery:
SELECT name
FROM Customers
WHERE customer_id IN (SELECT customer_id FROM Orders WHERE total_amount > 1000);In this example, the subquery (SELECT customer_id FROM Orders WHERE total_amount > 1000) retrieves the customer IDs from the "Orders" table for orders with a total amount greater than 1000. The main query then uses this subquery to select the names of customers from the "Customers" table whose customer IDs match the results of the subquery.
Question 7: What will the output of the given query be?
The code below is an example of a subquery:
SELECT First_Name, Last_Name, Cars_sold
FROM Cars_Details
WHERE cars_sold > (SELECT AVG (cars_sold)
FROM Cars_Details);Output:

Running the code will return the columns First_Name, Last_Name, and Cars_sold from the table Cars_Details, but only where cars_sold is greater than the average number of cars sold.
Question 8: Is there a difference between a NULL value and zero?
Yes! A NULL value in SQL represents the absence of data or information. It is a quantitative concept as it signifies the lack or unknown nature of a value. In other words, NULL indicates that we don't have knowledge about the actual value.
On the contrary, zero has a qualitative nature as it represents a specific value that equals zero. Zero is a distinct quantity, unlike NULL which denotes the absence or indeterminacy of a value.
Question 8: How would you filter data using JOIN?
The basic meaning behind JOIN is that it will return data from one table when that data is equal to the data in a second table. If you combine it with the WHERE clause, JOIN can be used for filtering data.
The first table is named Cars_Information with the following information:
Create table Cars_Information (Model_ID VARCHAR(20), Brand_ID VARCHAR(20), Brand_Name VARCHAR(20), Year_of_Production INT);
INSERT INTO Cars_Information (Model_ID, Brand_ID, Brand_Name, Year_of_Production) VALUES ('Z209BA1', 0025, 'Ford', 2016 );
INSERT INTO Cars_Information (Model_ID, Brand_ID, Brand_Name, Year_of_Production) VALUES ('B300MD4', 0954, 'Suzuki', 2023 );
INSERT INTO Cars_Information (Model_ID, Brand_ID, Brand_Name, Year_of_Production) VALUES ('M964OP0', 0012, 'NEXA', 2021 );
INSERT INTO Cars_Information (Model_ID, Brand_ID, Brand_Name, Year_of_Production) VALUES ('O860VL9', 9001, 'MG', 2018 );Output:
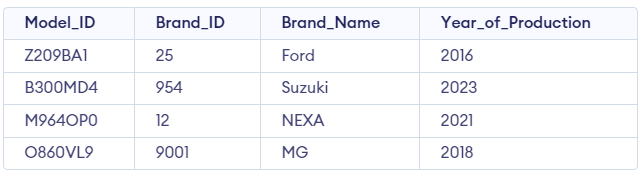
The second table is Cars_Production_Details with the following information:
Create table Cars_Production_Details (Brand_Name VARCHAR(20), Car_Name VARCHAR(20));
INSERT INTO Cars_Production_Details (Brand_Name, Car_Name) VALUES ('Ford','Figo');
INSERT INTO Cars_Production_Details (Brand_Name, Car_Name) VALUES ('Suzuki','Swift');
INSERT INTO Cars_Production_Details (Brand_Name, Car_Name) VALUES ('NEXA','Baleno');
INSERT INTO Cars_Production_Details (Brand_Name, Car_Name) VALUES ('MG','MG Asta');Output:
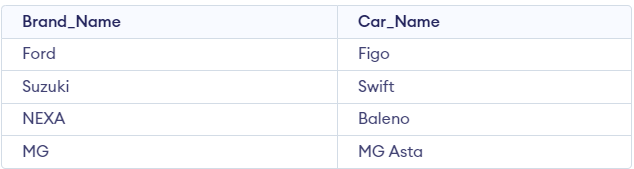
What would you do if you are asked to find all the models that were produced before 2016? Here’s the code:
SELECT Model_ID,
Brand_ID, Year_of_Production
FROM Cars_Information JOIN Cars_Production_Details ON Cars_Information.Brand_Name = Cars_Production_Details.Brand_Name
WHERE Year_of_Production < 2016;Question 10: How would you extract the last four characters from a string?
To extract the last four characters from a string, we will be using the SUBSTRING function.
Let's create a Product_Details table that contains Product_Name and Product_Manufacturer:
Create table Product_Details (Product_Name VARCHAR(20), Product_Manufacturer VARCHAR(20));
INSERT INTO Product_Details(Product_Name, Product_Manufacturer) VALUES ('Y999 Hammer 2020', 'John Hammer');
INSERT INTO Product_Details(Product_Name, Product_Manufacturer) VALUES ('MRF Tyres B457 2023', 'MRF Tyres');
INSERT INTO Product_Details(Product_Name, Product_Manufacturer) VALUES ('Red Cherry Paint 0078G5 2017', 'Asian Paints');
INSERT INTO Product_Details(Product_Name, Product_Manufacturer) VALUES ('Rosewood B6N0 2022', 'Wood Picker');Output:
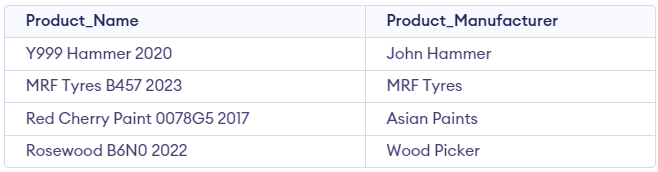
We need to find the year when the product was manufactured. In the above table, you can see that there is no column where the year of production details. But, in the Product_Name column, the year is mentioned.
So, we will extract the last string (Year of production) from the Product_Name column and make a new column "Year of Production".
Consider the below code to extract the year:
SELECT
Product_Name,
Product_Manufacturer,
SUBSTRING(Product_Name, LENGTH(Product_Name)-3, 4) AS year_of_production
FROM
Product_Details;The given SQL query selects three columns from the "Product_Details" table: "Product_Name," "Product_Manufacturer," and "year_of_production." The "year_of_production" column is created using the substring function.
In the substring function, we extract a portion of the "Product_Name" column. The substring starts from the third character from the end (i.e., the length of "Product_Name" minus three) and includes the next four characters. This portion represents the year of production.
Output:

Question 11: What is a view? How do you create one?
A view is like a virtual table or a stored SQL statement that utilizes data from one or more existing tables. It acts as a "virtual table" because it allows you to access and use the data as if it were a real table, but the data is retrieved dynamically whenever the view is accessed or queried. It's important to note that the result of a view is not physically stored as a separate table in the database. Instead, it is generated on the fly based on the underlying tables whenever the view is executed.
Let's create a table "Employee_Salary" which includes First_Name, Last_Name and Salary:
Create table Employee_Salary (First_Name VARCHAR (50), Last_Name VARCHAR(50), Salary INT);
INSERT INTO Employee_Salary(First_Name, Last_Name, Salary) VALUES ('Rahul', 'Sharma', 20000);
INSERT INTO Employee_Salary(First_Name, Last_Name, Salary) VALUES ('Aishwarya', 'Mahajan', 15000);
INSERT INTO Employee_Salary(First_Name, Last_Name, Salary) VALUES ('Pranav', 'Mishra', 35000);
INSERT INTO Employee_Salary(First_Name, Last_Name, Salary) VALUES ('Shanky', 'Singh', 23000);Output:
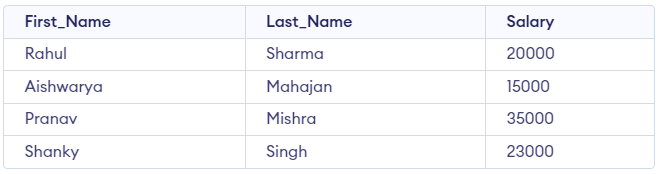
To maintain confidentiality while allowing access to the list of employees, you can create a view for the employees. This approach ensures that everyone in the company can access the latest employee data without exposing confidential salary information.
By creating a view, you can control the specific columns and data that are visible to users, while keeping sensitive information hidden. The view can be designed to include only the necessary employee details such as names, positions, departments, and other non-confidential information.
Here's how you can create a view:
CREATE VIEW Employee_details AS
SELECT First_Name, Last_Name
FROM Employee_Salary;when employees query the view, they will retrieve the desired employee information without being able to see the sensitive salary data. The view serves as a filtered and secure representation of the original employee table, ensuring that confidentiality rules are not violated.
The above code will only create a view, and will not retrieve any data. To retrieve the data, consider the below code:
SELECT * from Employee_details;Output:

Comments